

Представим реляционную базу данных как огромный склад. В его многоэтажных стеллажах хранятся коробки с ценной информацией. Они содержат данные по совершенным заказам, просмотрам страниц, транзакциям и т.д. Искать вручную несколько нужных коробок — непосильный труд. Если не справляется человек, за задачу берется автономный мобильный робот, заточенный под перемещение и ориентирование на складе. Роботы бывают разные: транспортные, подъемные, сортировочные. Они как функции в языке запросов SQL — для каждой задачи с коробками требуется уникальный запрос. В результате их работы мы получаем понятные отчеты за считанные секунды. Хотя пласт информации массивный, все коробки найдены, а их содержимое отсортировано.
Сегодня разберемся в SQL — что это такое и как писать запросы для ежедневных задач. Вы узнаете, как извлекать информацию, считать метрики и находить закономерности. После прочтения сможете самостоятельно анализировать продажи, поведение пользователей или эффективность рекламы.
Основы: что умеют SQL-запросы
SQL-запросы — это команды для работы с хранилищем информации. Они выступают точными инструкциями, написанные кодом, которые могут звучать как: «Покажи всех клиентов из Москвы» или «Посчитай выручку за июнь». База отвечает мгновенно.
Главная задача запроса — извлекать и обрабатывать данные. Можно выбирать строки, считать суммы, находить максимумы или объединять информацию из разных источников. SQL обрабатывает миллионы записей за секунды (быстрее, чем Excel управляется с тысячью строк).
Начнем с простого. Хотите увидеть список покупателей — команда «SELECT» вытащит искомые строки из конкретной таблицы. Подсчитать сумму совершенных заказов — функция «SUM» выступит умным калькулятором.
Ниже — команда для извлечения имен покупателей вместе с email из таблицы users:

Выборка данных: находим то, что нужно
Чтобы достать конкретные данные, применяется фильтрация. Например, для определения активных пользователей, заказов дороже 5000 рублей или покупателей, которые не заходили полгода. Фильтры выставляют условия, и база выдает искомые строки.
Оператор «WHERE» работает как сито. Пишете условие — получаете отфильтрованный результат. Хотите заказы за последний месяц — укажите диапазон дат. Выделить завершенные покупки — добавьте проверку статуса.
Можно комбинировать несколько условий. Логика обычная: И, ИЛИ, НЕ. Ищете клиентов из Петербурга, сделавших покупку больше 10 тысяч? Два условия через «AND» — выборка готова.
Пример с «WHERE» для фильтрации по дате и сумме, используя операторы «AND» и сравнения:

Объединяем таблицы через «JOIN»
Реальные данные не хранятся в одном месте, а разбросаны по реляционной базе. Информация покупателей — в одной таблице, покупки — в другой, товары — в третьей. Полная картинка собирается как по паззлам.
«JOIN» склеивает строки из разных таблиц по общему полю. Представьте две стопки карточек: в одной — имена покупателей с ID, в другой — покупки с ID покупателя. Соединяем по ID — получаем полную историю покупок человека.
Типы соединений:
- «INNER JOIN» берет только совпадения: если посетитель ничего не купил, он не попадет в результат.
- «LEFT JOIN» покажет всех пользователей, даже без заказов — отсеивает неактивных пользователей.
Рассмотрим, как «INNER JOIN» применяется для связи таблиц customers и orders по полю customer_id:

Использование «LEFT JOIN» для поиска пользователей, где order_id равен «NULL»:

Команда выявляет пользователей, которые зарегистрировались, но не купили продукт. Полезно для запуска рекламных кампаний.
Агрегация и группировка: подсчет итогов
Аналитика — это не изучение отдельных строк, а результат их сложения в общую картину. Строками могут выступать:
- Количество заказов за месяц.
- Средняя сумма покупки.
- Кто самый активный клиент и т.д.
Чтобы провести полный анализ, отвечающий целям компании, потребуется агрегация. Функции типа «COUNT», «SUM», «AVG» берут на себя задачи математики. «COUNT» подсчитывает строки, «SUM» складывает числа, «AVG» находит среднее. Хотите узнать выручку — суммируйте столбец с ценами. Требуется средняя оценка товара — пропишите «AVG».
Но интереснее становится с группировкой. «GROUP BY» разбивает данные на категории, подсчитывая метрики для каждой. Например, разбиваете покупки по месяцам — видите динамику продаж. Группируете по товарам — понимаете, что продается лучше.
«GROUP BY» в связке с «COUNT» для подсчета количества покупкой по каждой категории товаров:

Иногда нужно отфильтровать сами группы. Допустим, показать только категории с больше чем 100 продажами. «WHERE» не работает — он фильтрует строки до группировки. Подойдет «HAVING» —отбирает уже готовые группы.
«HAVING» для отбора категорий, где «COUNT» заказов больше 100:

«CASE»: гибкая логика внутри запросов
Часто приходится добавлять новый столбец на основе условий. Разделить заказчиком на сегменты по сумме покупок, присвоить статус заявке в зависимости от срока доставки, или категоризировать возраст пользователей. «CASE» добавлять логику прямо внутри команды.
Работает как набор правил: если выполняется условие А — вернуть X, если условие Б — вернуть Y, иначе — Z. Синтаксис простой.
Пример для сегментации пользователей:
- Покупка до 1000 рублей — «базовый»
- от 1000 до 5000 — «стандартный»
- выше 5000 — «премиум».
«CASE» для создания столбца segment на основе суммы заказа: до 1000, от 1000 до 5000, больше 5000:
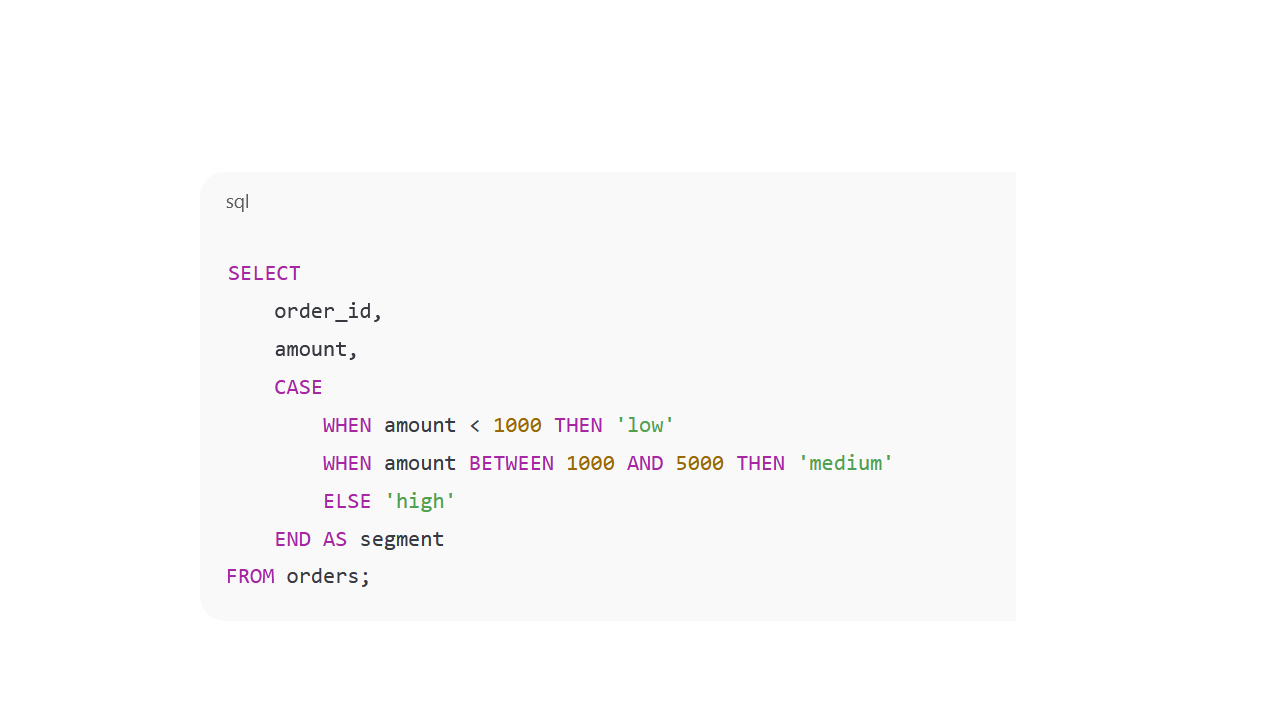
Один «CASE», и у вас новый столбец с категориями. Получаете сегментацию без дополнительных таблиц. Можно группировать по полю и считать, сколько клиентов в каждом сегменте.
Подзапросы: запросы внутри запросов
Хотите найти клиентов, чья покупка превышает среднюю по базе? Перед этим требуется посчитать среднее, потом сравнить с ним каждого клиента. Подзапрос справится за одно действие.
Вы пишете запрос внутри другого. Внутренний считает среднее, внешний использует это значение для фильтрации. Можно вкладывать подзапросы в «WHERE», «SELECT» или даже «FROM» — определяется задачей.
Подзапросы применяются и для сравнений. Найти товары дороже средней цены, отделы с зарплатой выше медианной, или продавцов, чья выручка выше среднего по компании. Одна команда покрывает две отдельные операции.
Подзапрос в «WHERE» для выборки покупкой с суммой больше средней, где среднее вычисляется через «SELECT AVG»:
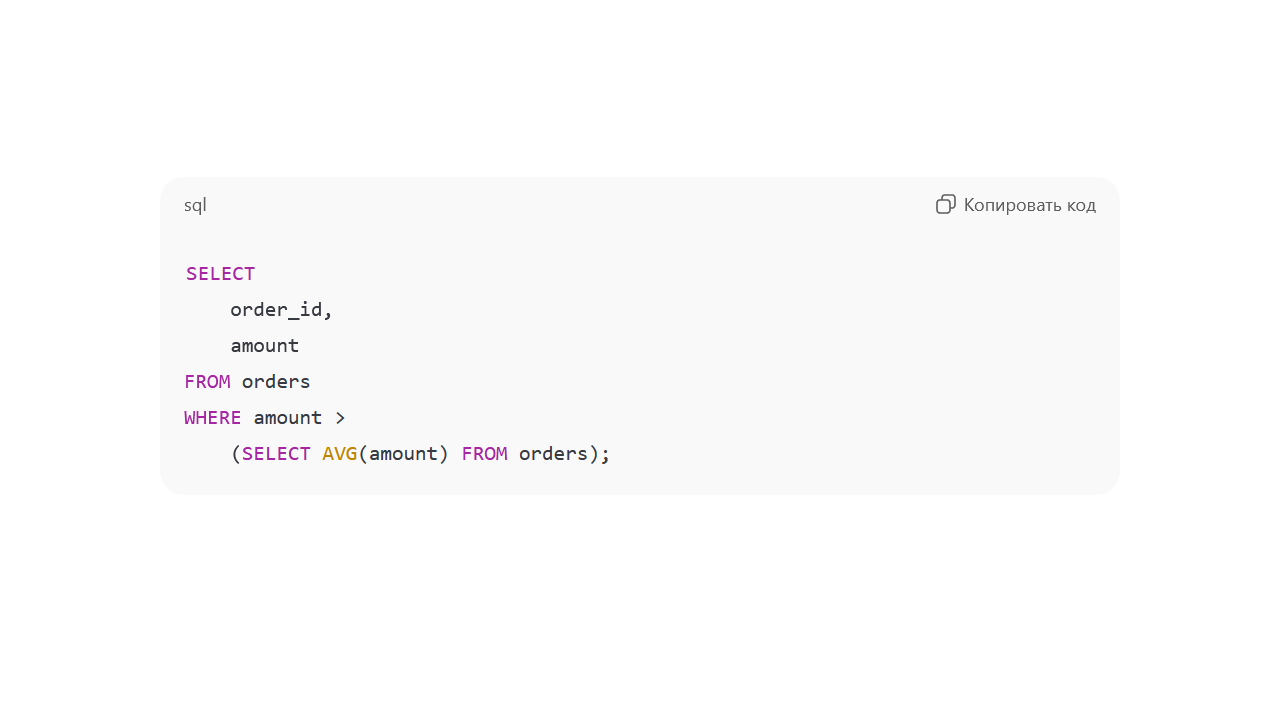
Здесь внутренний запрос считает среднюю сумму всех заказов. Внешний показывает только те, что выше этого значения.
Лайфхаки для аналитики
Приведем приемы аналитики для упрощения ежедневной работы.
Работа с датами. Задача — группировать по месяцам или годам. Функции «EXTRACT» или «DATE_PART» вытаскивают искомую часть из даты. Группируете по месяцу — видите сезонность продаж. Можно даже вычислять разницу между датами: сколько дней прошло от регистрации до первой покупки.
Процентные доли. Рассчитываете долю каждой категории в общей выручке? Делите сумму по категории на общую сумму, умножаете на 100. Можно сделать через подзапрос или оконные функции. Сразу видно: электроника дает 45% дохода, книги — 8%.
Поиск лидеров. Хотите узнать топ-5 самых продаваемых товаров? Сортируете строки по показателю через «ORDER BY», а потом ограничиваете вывод через «LIMIT». Получаете лучших — без лишнего. Работает для любых рейтингов: самые дорогие заказы, самые активные клиенты, города с максимальными продажами.
SQL-инструкция для вывода топ-5 продуктов по количеству продаж через «ORDER BY» и «LIMIT»:

Удаление дубликатов. Комбинация «COUNT» + «DISTINCT» дает точное количество уникальных покупателей. В то время как простой «DISTINCT» без «COUNT» показывает полный список. Без «DISTINCT» посчитались бы все покупки. С ним — от разных покупателей.
Использование «DISTINCT» для подсчета уникальных пользователей, сделавших заказы:

Текстовые операции. В базе данные неприбранные: лишние пробелы, разный регистр, опечатки. Функции «TRIM», «UPPER», «LOWER» приводят все к единому виду. Ищете «Иванов»? Переводите фамилии в верхний регистр перед сравнением — не пропустите «иванов» или «ИВАНОВ».
Оптимизация: как ускорить запросы
Медленные запросы съедают время и нагружают сервер. Три базовых правила ускорят работу в разы.
Создавайте индексы. Если постоянно фильтруете по одним и тем же столбцам — дате, ID пользователя, статусу заявки — добавьте на них индексы. База перестанет перебирать миллион строк и мгновенно найдет искомые. Полезно для полей в «WHERE» и «JOIN».
Ставьте условия отбора как можно раньше. Не загружайте год транзакций, чтобы потом выбрать один месяц. Укажите диапазон дат сразу в «WHERE» — база обработает выделенные строки вместо миллионов лишних. Снижает объем вычислений.
Запрашивайте только нужные столбцы. «SELECT *» выгружает все поля таблицы, даже если вы используете три из пятидесяти. Перечисляйте конкретные столбцы — ускорите выполнение, сократив объем передаваемой информации.
Правильная оптимизация превращает запрос на минуту в секундное поручение. SQL запросы для аналитики должны давать ответ мгновенно — иначе теряется смысл быстрого анализа.
Заключение
Аналитика начинается с вопроса и заканчивается ответом. Запросы — мост между ними. Чем лучше владеете языком, тем глубже понимаете бизнес и точнее делаете прогнозы. SQL — незаменимый инструмент для работы с цифрами. Применяйте его ежедневно, чтобы выбирать данные, объединять таблицы, считать метрики и находить закономерности. Берите реальные задачи, пишите запросы, смотрите на результаты. Привычка закрепиться, и с каждым разом вы будете действовать быстрее и увереннее.
Разместите его на онлайн-сервисе помощи студентам Студворк. Наши эксперты помогут вам в кратчайшие сроки. Размещайте свой заказ прямо сейчас!



Комментарии